Training an LLM on 150K Discord messages
Over the past few months I have been fascinated by this post by Izzy Miller, where he trains an LLM on his and his friends’ iMessage group chat history. In his case the idea developed from discovering iMessage used an SQLite database to store its messages locally on macs, from which he trained a model. I recommend reading it as I base a lot of this on what he did (with notable differences).
With that out of the way, let’s talk about my eventually successful process of creating fine-tuning a language model with Discord messages.
Gathering the data
To train on a Discord message history, it’s a good idea to… have the history. In theory, you could gather those messages from the discord API while training, and generate your dataset that way, but generally speaking it’s a better idea to have them locally in a database, which lets you query the messages and fine-pick what you want to leave in and out.
A few months ago I wrote a tool called DiscordDumper that does this job well enough. It needs bot access to the server you want to gather messages from (theoretically you should be able to do this with a user token and avoid needing bot access, but I had a bot where I was collecting the data from). This takes a while, because Discord will rate-limit you every few requests. When it’s done, you’ll end up with an SQLite database looking like this: 
Formatting the data
In principle, using a text completion model should be able to use the last message of a chat history to a generate another chat message. sort of like this:  being completed with :
being completed with :  But I’d like to be able to give the bot a bit more depth than generating message after message. Strings of individual messages is not that much data, and it likely doesn’t capture the context of the chat all that well. Izzy talks about how the Stanford alpaca project used a formatting style that led to good results, so we can do something similar.
But I’d like to be able to give the bot a bit more depth than generating message after message. Strings of individual messages is not that much data, and it likely doesn’t capture the context of the chat all that well. Izzy talks about how the Stanford alpaca project used a formatting style that led to good results, so we can do something similar.
So, we need to work our dataset into prompt/input/response pairs, like this:
1
2
3
4
5
{
"instruction": "You are a sheep, and you answer questions exclusively with 'Baa'. ",
"input": "Sheep, what is the answer to life, the universe, and everything?",
"output": "Baa."
}
This also gives me a chance to add the last few chat messages, to add context to what is going out. Timing within group chats is rather asynchronous and the time between conversations can be pretty far apart. So, to generate our dataset, we have to split it into “conversations” of a few hours. Izzy does this by using a SQL query to split the chat history into sessions, but I was more comfortable doing it in python instead.
Doing this however, I ran into a few issues that are specific to discord chats, and an iMessage chat history doesn’t have:
- Usernames: Within my group, people mostly know and refer to each other by first name, and the “username” property I have in my data doesn’t really reflect that.
- Mentions! people on medium-large discord servers of course mention each other all the time, and discord translates that to
<@[userID]>when you try to fetch the text content of those messages. - Hyperlinks: If a message is just an image, we can’t really do anything with it, as it’s just a hyperlink.
- Channels: a message in channel A is (usually) not related to a message in channel B. So, I had to remove hyperlinks, and add a way to turn mentions and usernames back into “real”* names. I put “real” in quotation marks, because for some people these are not their actual names, but they names they are most commonly mentioned by.
So I gathered the ~30 or so people that had sent more than 300 messages in the server over the past few years, and made a JSON file that used their discord ID’s as the key, and their “real” names as the value:
1
2
3
4
5
{
"[REDACTED]" : "Damon",
"[REDACTED]" : "Timo",
"[REDACTED]" : "Jinx"
}
1
2
3
4
5
6
7
8
def resolve_realname(userid: str) -> str:
realname : str
if userid in ids_realnames:
realname = ids_realnames[userid]
else:
realname = "unknown"
return realname
now that we can resolve ID’s to names, we can label messages with real names as opposed to usernames, and replace mentions of ID’s with mentions of names:

While we’re at it, we can also remove links (and messages that are only links) from the dataset:
1
text = re.sub(r'http\S+|www\S+|https\S+', '', text, flags=re.MULTILINE)
and now that we have our set of mostly clean, understandable messages, we can divide them up into conversations:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Message:
def __init__(self, content: str, sent: datetime, channelname: str, sender_id: str) -> None:
self.content = content
self.sent = sent
self.channelname = channelname
self.sender_id = sender_id
class Conversation:
def __init__(self, starttime: datetime, channel: str) -> None:
self.messages: list = []
self.channel: str = channel
self.starttime: datetime = starttime
def add_message(self, message: Message):
self.messages.append(message)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
for (content, sent, channelname, sender_id) in data:
#some code is left out, check on the linked Github page for the full file
if not message_content:
continue
message_date : datetime
#Try getting message date
try:
message_date = datetime.strptime(sent, "%Y-%m-%d %H:%M:%S.%f")
except ValueError:
#discord only stared adding microseconds to message dates some time in 2021-2022
message_date = datetime.strptime(sent, "%Y-%m-%d %H:%M:%S")
message = Message(message_content, message_date, channelname, sender_id)
#if the last message is 4 hours old, in another channel OR nonexistent - start a new conversation
if ( last_message is None or last_message.sent < (message.sent - timedelta(hours=4)) or message.channelname != current_conversation.channel):
current_conversation = Conversation(message.sent, message.channelname)
all_conversations.append(current_conversation)
#add the message to the ongoing conversation
current_conversation.add_message(message)
last_message = message
And, now that we have all of the conversations, we can turn these conversations into prompt/input/output sets to train our LLM on:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
print("Creating dictionary with prompts and input/outputs")
for conversation_index, conversation in enumerate(all_conversations):
for index, message in enumerate(conversation.messages):
real_name = resolve_realname(message.sender_id)
try:
last_messages = conversation.messages[0:index - 1]
except IndexError:
last_messages = []
named_last_messages = ""
for message in last_messages:
named_last_messages += f"{resolve_realname(message.sender_id)} : {message.content} \n"
prompt = f"You are {real_name}. You are in a chat room with some of your friends you've known for a while, and some people that left that have been named \"unknown\" you chat unfiltered, and saying rude things and swearing are encouraged. you will be presented with a short chat history, and your task is to respond how {real_name} would."
training_output.append({
"instruction" : prompt,
"output" : message.content,
"input" : named_last_messages
})
If you’re doing this on large servers and have low storage space I want to warn you: in a conversation with 20 messages, this produces 20 prompts, but a lot of that is the same messages getting repeated over and over per input. It works for generating large datasets though.
Now that we’ve got our dataset, we can start training:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
from datasets import load_dataset
from trl import SFTTrainer
import transformers
dataset = load_dataset("json", data_files = "input_output_dataset.json", split="train")
model : transformers.AutoModelForCausalLM = transformers.AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
tokenizer = transformers.AutoTokenizer.from_pretrained("facebook/opt-125m")
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
def formatting_prompts_func(examples):
output_text = []
for i in range(len(examples["instruction"])):
instruction = examples["instruction"][i]
input_text = examples["input"][i]
response = examples["output"][i]
text = f'''Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input_text}
### Response:
{response}
'''
output_text.append(text)
return output_text
trainer = SFTTrainer(
model,
tokenizer=tokenizer,
train_dataset=dataset,
formatting_func=formatting_prompts_func,
max_seq_length=512,
packing=False,
dataset_batch_size=16
)
#model.cuda() #you can turn this on if you have a good GPU for training, but my poor 1660 super was barely an improvement over my R5 3600
trainer.train()
trainer.save_model("model.bin")
And when that is done, we should have a model for training. stay tuned for a few weeks, when i have the results.
The results
About two weeks of training later, we have our fully trained model!
Hugging face has a nice pipeline for the generation of text with trained models, so generating the messages isn’t all that difficult:
1
generator = pipeline('text-generation', model="./model.bin", max_length=2000, device=0)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def generate_message(input_messages: list[str], real_name: str) -> str:
formatted_input = "\n".join(input_messages)
text = f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
f"You are {real_name}. You are in a chat room with some of your friends you've known for a while, and some people that left that have been named \"unknown\" you chat unfiltered, and saying rude things and swearing are encouraged. you will be presented with a short chat history, and your task is to respond how {real_name} would."
### Input:
{formatted_input}
### Response:
"""
completed_text = generator(text, do_sample=True, temperature=1, skip_prompt=True)
formatted_response = f"{real_name}: {message.strip()}"
return formatted_response
And now that we have a function for generating a chat message, we can plug this into a discord bot to unleash upon this world.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#A lot of this script has been removed to make it a *bit* more concise
import discord
Client = discord.Client(intents=discord.Intents.all())
channel_id = os.getenv("CHANNEL_ID")
token = os.getenv("TOKEN")
@Client.event
async def on_message(message: discord.Message):
global is_generating # Avoid generating multiple messages at the same time, my PC cannot handle this.
if is_generating:
return
is_generating = True
async with message.channel.typing():
# (Determine who sent the message and their real name)
# Remove URLs, mentions, and hashtags
filtered_content = re.sub(r'http\S+|www\S+|https\S+', '', filtered_content, flags=re.MULTILINE)
#Format the message
formatted_message = f"{sender_realname}: {filtered_content}"
#Put it into the history, do not let history grow greater than 3 messages
if len(message_history) > 4:
message_history.pop(0)
message_history.append(formatted_message)
#(Determine person to respond as, my logic for this got a bit out of hand)
message_to_reply = generate_message(message_history, replying_person)
await message.channel.send(message_to_reply)
is_generating = False
Client.run(token)
And when that is running, the bot can start generating messages, it quickly showed that the model that I used to train on, (opt-125m) is not really a good fit for larger contexts and prompts.
Sometimes I’d get legible text.
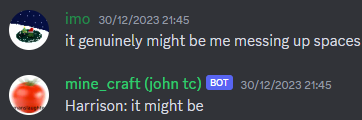
Sometimes it would just repeat exactly what you would say to it.
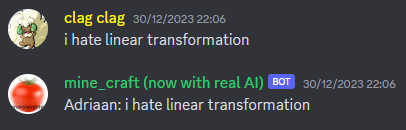
Sometimes it would just…

Ultimately, It was pretty funny for the few hours I had it running.

Closing thoughts
In retrospect, taking two weeks to fine-tune a model that was already a bit too small was probably a bit of a waste of my time. If i had to do it again i’d probably
- Take a bigger model as a starting point: If I’d used LLaMa or Mixtral, I’d have gotten better results. The issue with using those initially was not having a PC that can run or train either, but if a cloud provider comes along and offers a good price for some credits I might try again.
- Filter out specific channels a bit better! I completely forgot we had a counting channel, and at several points I got confused as to why the bot was spitting out numbers. I’d like to try again at some point later. For now it’s been fun. Learned a lot about how LLM’s work, and I’m pretty hopeful for where it’s all going.